大纲
- 来源:linkedin开源:a distributed streamed platform
- databus
- cubrect
- parseq
- kafka
stream platform has three key capabilities
- 特性
- 消息队列 mq
- 数据存储 db
- 流处理 stream
- 构建实时流管道,实时处理数据流 real time & transform react
3.面向于数据流的生产、消费、存储、处理
3-1 基本概念
物理概念(服务器|| 硬件|| 载体…)
逻辑概念(策略 逻辑…)
- producer
消息和数据的生产者,向一个topic发送消息的
- 进程
- 代码
- 服务
- consumer
消息和数据的消费者,订阅数据topic并且处理器发布的消息的
- 进程
- 代码
- 服务
- consumer group 逻辑概念
消费组,针对同一个topic,会广播给不同的group,一个group中,只有一个consumer可以消费该消息。 - broker 物理概念
kafka集群节点之一, - topic 逻辑概念
kafka消息的类别,对数据进行分类 区分 隔离 - partition 物理概念
kafka下数据存储的基本单元,一个topic会被分散处理存储到多个partition,每个partition是有序的,但是每个topic无法保证有序。 - replication
同一个partition可能会有多个raplica,多个replica之间数据时一样的 - replication leader
多个replication副本之间需要一个且只有一个leader major负责该partition与producer和consumer交互,其他的replication是副本,只负责同步数据。 - replica manager
负责管理当前broler所有分区和副本的信息,处理kafka controller 发起的请求,副本状态的切换 ,添加 读取消息等,选举出一个replication leader
3-2更多的kafka基本概念
- partition
- 每个topic被切分称多个partitions
- 消费者的数目小于或者等于partiton的数目
每一个消费者会消费一个partition,如果消费者数目大于partition的数量,会出现一个partition被多个消费者消费 - broker group中的每一个broker保存topic的一个或多个partition,注意区别对待consumer group,同一个partion不会被保存在相同的broker上。如果partion非常大,可以用多个broker保存,而不是说一个partition被保存了多份在一个broker上。
- comsumer group中仅有一个consumer 读取topic的一个或者多个partion,并且是唯一的consumer,一个partition只能被这一个consumer消费,可以参考第二条
- 为什么要有consumer group
为了容错,group有容错机制?
为了提高性能?后续再讲 - replication 副本
当集群中有broker挂了,partition ,系统可以主动使replications提供服务,系统默认每个topic的replication系数为1,可以在创建topic时单独设置 - replication
基本特点是topic的partition
所有的读和写都从followers,follower必须能够及时复制leader数据
增加容错性和可扩展性3-3 kafka基本结构
![image][1]
数据从productor流向consumer,
kafka暴露四个接口 - connectors api
- stream processors api
- producer api
- consumer api
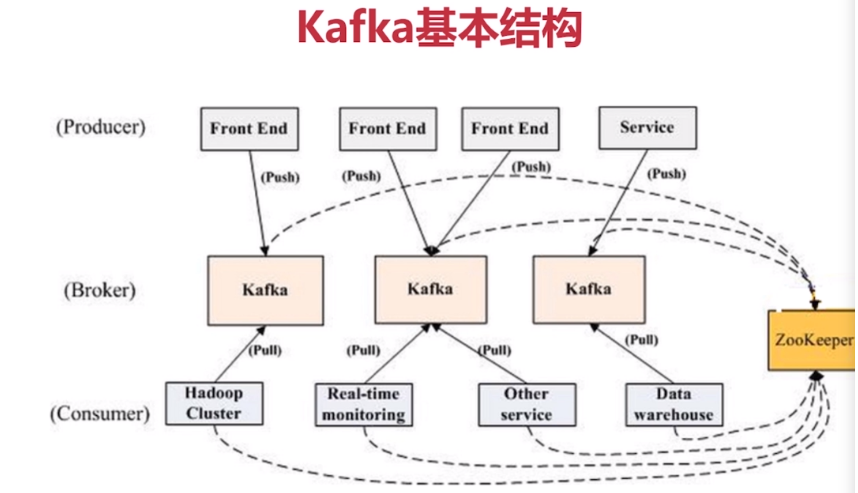
kafka强依赖于zp,broker信息、topic、partition的分布
应用包括: - hadoop
- 实时监控
- 数据仓库
- 其他…
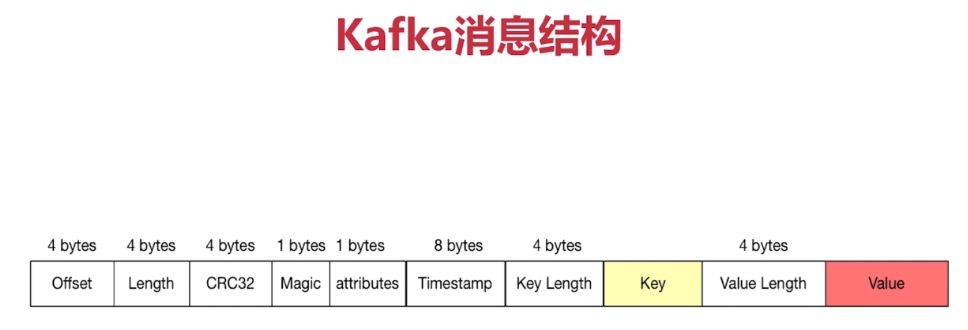
- offset 当前消息所处的偏移量 4字节
- length 当前消息整体长度 4字节
- crc32 校验当前消息完整性 4字节
- magic 分布式系统一般都设计为这个字段,固定的一个字段。可以快速的判定是不是kafka的消息。如果不是,则扔掉,不需要经过校验等动作
- attributes 放置当前消息属性 1字节 枚举值
- timestamp 消费时间戳 8字节
- key length 4字节
- value 无限制
- value length 4字节
- value 无限制
3-4 kafka特点
- 分布式
- 多分区 partition
- 多副本 replication
- 多订阅者
topic可以有一个或者多个订阅者,每一个订阅者只能有一个partition - 基于zookeeper调度
- 高性能
- 高吞吐量 几十万/s
- 低延迟
- 高并发
- 时间复杂度o(1)
- 持久性和扩展性
- 数据可持久化
- 容错性 按组消费 多副本
- 支持在线水平扩展 增加新机器就可以放topic和partion
- 消息自动平衡 consumer group 避免消息过于集中在某几台服务器,在服务端和消费者两端自动平衡,怎么实现的?
3.5 应用环节
- 消息队列 分区、副本、持久化、稳定、重复消费、低延迟…
- 行为跟踪 发布订阅模式的扩展应用 在线或者离线应用
- 元信息监控 运维数据监控
- 日志收集 elk flume ,kafka可以让日志活起来,低延迟,支持更多的数据源和消费者,脱离以文件为中心的日志收集
- 流处理 收集上游 处理在下游 对一个topic多次处理后再次处理,分段式链路流处理
- 事件源 记录状态转移序列 回溯事件变更 存储日志 动态汇总
- 持久性日志 commit log 日志压缩 通过对日志回溯,
3.5 kafka简单案例
- 环境启动
- 下载zookeeper
- kafka下载
- 解压、环境变量、配置文件…
- zookeeper-server-start
- bin/kafka/-topics –create – zookeeper 127.0.0.1:2181 –replication-factor 1 –partition s 3 –topic imooc-kafka-topic
- bin/kafka-topics –list –zookeeper 127.0.0.1:2121
- 隐藏分区 __consumer_offsets
- 启动producer /bin/kafka-console-producer –broker-list
- 启动消费者 /bin/kafka-console-comsumer –bootstrap-server 127.0.0.1:9002 –topic imooc-kafka-topic –from-beginning
- 简单生产者
- 简单消费者
4-3 kafka代码案例
基于java spring boot
java代码真的挺有意思的,比php的好看 有艺术多了
5-1 kafuka高级特性-消息事务
- 为什么要支持事务
- 要支持读取-处理-写入模式 ,要保证数据一致性
- 流处理需求的增加增强
- 需要更准确的数据处理结果
- 数据传输事务的定义
- 最多一次:消息不会被重复发送,最多被传输一次,但也可能一次也不传输
- 最少一次:消息不会被漏发,最少被传输一次,但可能重复传输。但最好消息方最好幂等操作
- 精确的一次 exactly once:不会漏也不会重复,仅仅一次,最优美。不会丢失,不会重复。
- 事务保证
- 内部重试问题
procedure 幂等处理(自身已经处理好) - 多分区原子写入
读取 -处理-写入 如何实现原子性?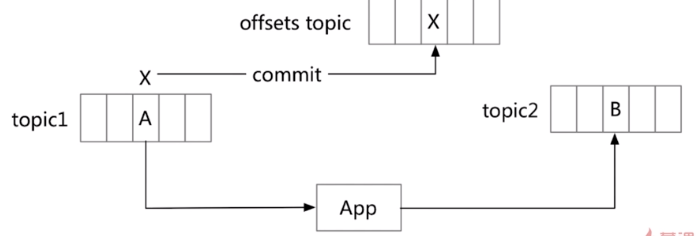
也就是说如何保证成功消费(从topic 1)并且发布(到topic2)
X为偏移量,会被标记成已消费,并写入到一个内部的kafka的topic(offset topic),记录office commit,此时认为被成功消费(已经提交了偏移量) - 事务保证-避免僵尸实例
- nginx rocketmq netty kafka都具有实现了这种技术
- 网络传输持久性日志块(生产和消费的消息)
- java nio channel.transforTo方法
- linux sendfile 系统调用
- 文件传输到网络的公共数据路径
1.操作系统将数据从磁盘读入到内核空间的页缓存- 应用程序将程序从内核空间读入到用户空间内存中
- 应用程序将数据写回到内核空间的socket缓存中
- 操作系统将数据从socket缓冲区复制到网卡缓冲区,以便将数据从网络发出
- 以上为4次拷贝,才能从磁盘到达网卡
- 零拷贝过程
- 操作系统将数据从磁盘读入到内核空间的页缓存
- 将数据的位置和长度的信息的描述符增加至内核空间的socket缓冲区中
- 操作系统将数据从内核拷贝到网卡缓冲区,以便将数据从网卡发出
- 此处的零拷贝指的是内核空间和用户空间的交互拷贝为0
- 文件传输到网络的公共数据路径的演变
从
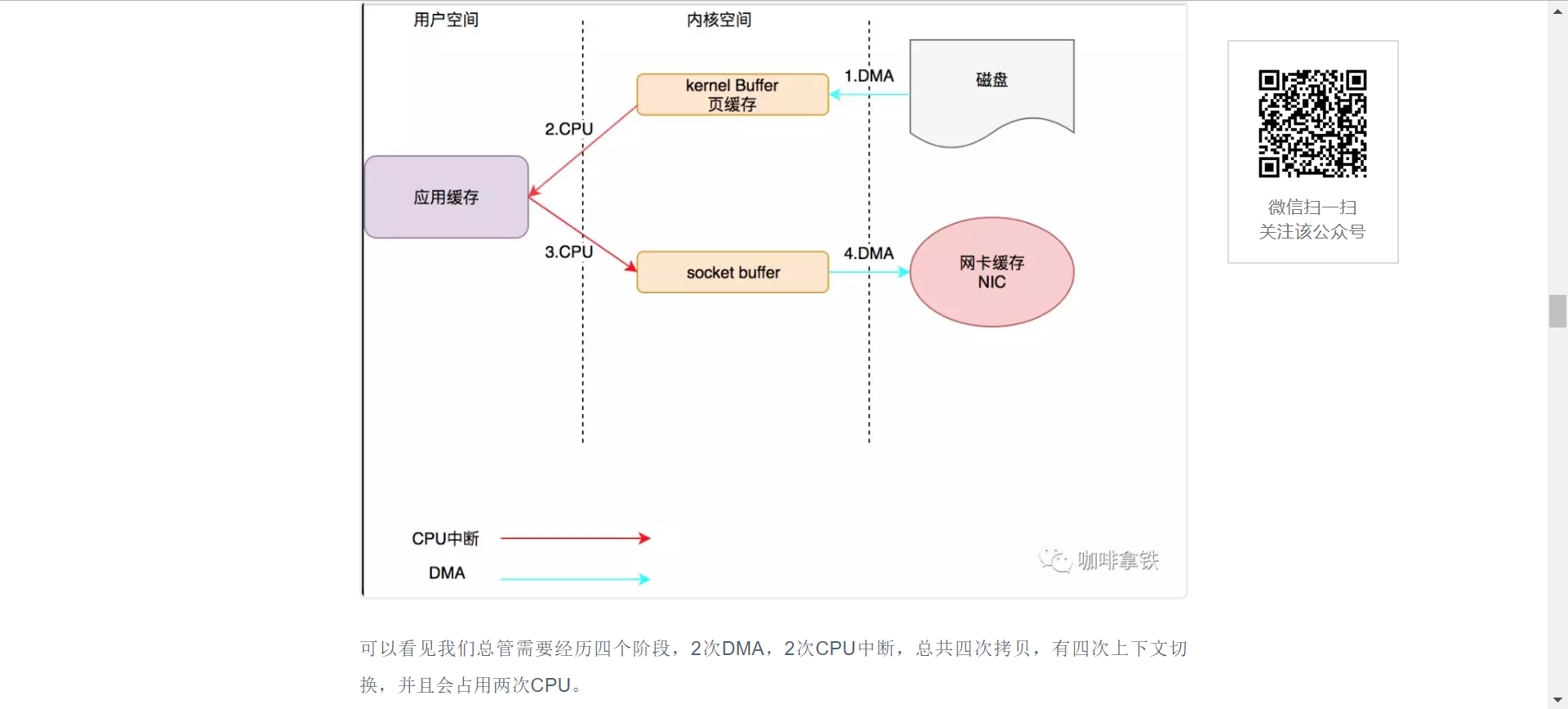
1. CPU发指令给I/O设备的DMA,由DMA将我们磁盘中的数据传输到内核空间的内核buffer。
2. 第二阶段触发我们的CPU中断,CPU开始将将数据从kernel buffer拷贝至我们的应用缓存
3. CPU将数据从应用缓存拷贝到内核中的socket buffer.
4. DMA将数据从socket buffer中的数据拷贝到网卡缓存。
改为NIO
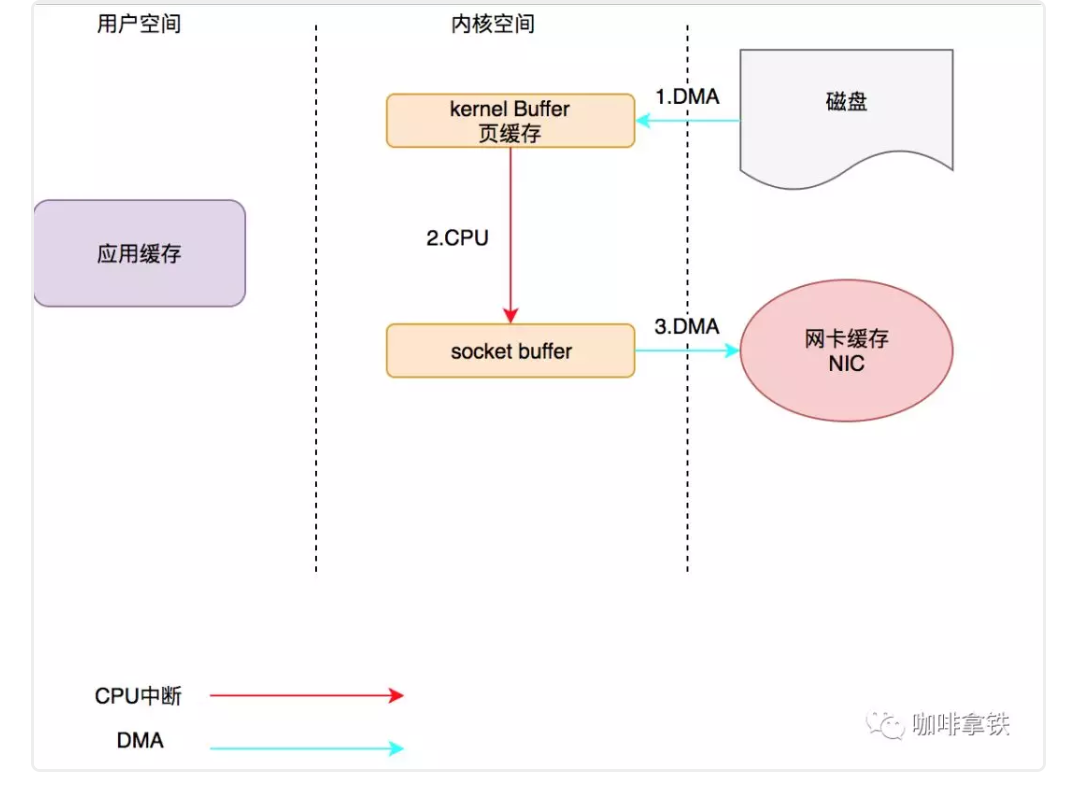
1. 调用sendfie(),CPU下发指令叫DMA将磁盘数据拷贝到内核buffer中。
2. DMA拷贝完成发出中断请求,进行CPU拷贝,拷贝到socketbuffer中,sendFile调用完成返回。 3.DMA将socket buffer拷贝至网卡buffer。
- 补充-零贝定义:
在计算机在网络上发送文件时候,不需要将文件内容拷贝到用户空间(user space) 而直接在内核空间 (kernel space )中传输到网络的形式。
[1]: /img/kafka/kafka_basic_construct.png